'%3e%3cellipse%20cx='185.202'%20cy='292.401'%20rx='236.2'%20ry='212.4'%20transform='rotate(180%20185.202%20292.401)'%20fill='url(%23paint0_radial_6113_7068)'/%3e%3c/g%3e%3cdefs%3e%3cfilter%20id='filter0_f_6113_7068'%20x='-130.996'%20y='0.000976562'%20width='632.398'%20height='584.8'%20filterUnits='userSpaceOnUse'%20color-interpolation-filters='sRGB'%3e%3cfeFlood%20flood-opacity='0'%20result='BackgroundImageFix'/%3e%3cfeBlend%20mode='normal'%20in='SourceGraphic'%20in2='BackgroundImageFix'%20result='shape'/%3e%3cfeGaussianBlur%20stdDeviation='40'%20result='effect1_foregroundBlur_6113_7068'/%3e%3c/filter%3e%3cradialGradient%20id='paint0_radial_6113_7068'%20cx='0'%20cy='0'%20r='1'%20gradientUnits='userSpaceOnUse'%20gradientTransform='translate(-43.0144%20248.324)%20rotate(-25.0248)%20scale(462.733%20514.489)'%3e%3cstop%20stop-color='%23FF9DDA'/%3e%3cstop%20offset='0.44'%20stop-color='%23F7FF9D'%20stop-opacity='0.52'/%3e%3cstop%20offset='0.84'%20stop-color='%23FF8B7B'%20stop-opacity='0.2'/%3e%3cstop%20offset='1'%20stop-color='%23F7FF9D'%20stop-opacity='0'/%3e%3c/radialGradient%3e%3c/defs%3e%3c/svg%3e)




Faros AI's 2025 study of more than 10,000 developers found a 21% productivity gain at the individual developer level. Project velocity barely moved. The conventional explanation — that review and testing have slowed under the volume of AI-generated code — is true but incomplete. AI accelerated requirements generation too, and the work before the IDE is now producing more, less complete inputs. The stages after the integrated development environment (IDE) are doing exactly what they were designed to do: absorbing the cost. Until the front of the cycle gets a governed single source of truth, the productivity gains will keep getting consumed before they reach the P&L.
Why AI coding tools haven't moved the delivery cycle
I've spent the last four weeks talking with CIOs at large enterprises — Fortune 500 insurers, major banks, global investment services, biotech instrumentation, and aviation manufacturers. Different industries, different regulatory postures, different team sizes — and the same question in every conversation.
Their developers are measurably faster with AI coding tools. Their CFOs can't find the gain on the P&L.
The numbers are real. Faros AI's 2025 telemetry study of more than 10,000 developers found that teams with high AI adoption completed 21% more tasks and merged 98% more pull requests — but organizational delivery metrics stayed flat. The 2025 DORA report from Google Cloud, surveying nearly 5,000 developers, shows the same pattern: AI now correlates positively with throughput, but software delivery instability remains elevated. The 2024 DORA report was even blunter — every 25-point increase in AI adoption corresponded to a 1.5% throughput drop and a 7.2% stability drop.
To justify the AI investment at enterprise scale — licenses, retraining, security review, governance — CIOs are being asked for 30 to 50 percent improvements in end-to-end delivery cost. Almost nobody is getting them.
A divisional CIO at one of the insurers put it to me plainly: "AI tools have made individual developers dramatically more productive. But our delivery cycle is not shortened at the same rate."
Where is the gain going?
21% more tasks completed. 98% more pull requests merged. Organizational delivery metrics: flat. — Faros AI, 2025
The downstream is doing its job — under a load it wasn't built for
The conventional answer is well-documented and worth taking seriously.
The cycle hasn't changed; some of its stages got dramatically faster, and the others are absorbing the consequence.

The stages after the development step are doing exactly what they were built to do. Testing catches bugs. Review catches issues. Architecture review enforces conformance. Governance gates prevent code from shipping until it's been validated. Those processes work — and that's why velocity hasn't moved. They were sized for a slower upstream. They're now absorbing a much higher volume of code, against less complete inputs from the stages before the IDE.
"We've seen faster development. We've also seen more defects going to the testing phase." — CIO at a Regional Bank
More defects don't mean testing failed. They mean testing is doing its job — catching things before they ship. The bottleneck isn't a process breakdown. It's a load problem.
Scaling review capacity, adding test environments, bringing in more senior engineers — that's what most engineering organizations are already doing. It doesn't move the cycle, because the constraint isn't downstream.
The downstream is stressed because AI made code and document generation cheap.
The upstream SDLC broke too — and it gets less attention
The half of the diagnosis that's missing sits before a line of code is ever written.
Vipin Jain captured the edge of it in CIO Magazine last week: "The first real bottleneck appears upstream when acceptance criteria are too loose for the agent to interpret safely. The teams that struggle most are not the ones with weak prompts. They are the ones with vague intent. AI amplifies ambiguity as efficiently as it amplifies insight."
He's right, and I'd take it further. The upstream isn't just ambiguous. It's faster and less complete at the same time.
The reason is simple. AI didn't only speed up code generation. It sped up requirements generation. The same LLMs developers use to write code, business stakeholders are using to create unstructured documents. Everything before the IDE got faster too. Nobody planned for what that would do.
Four things go wrong at once.
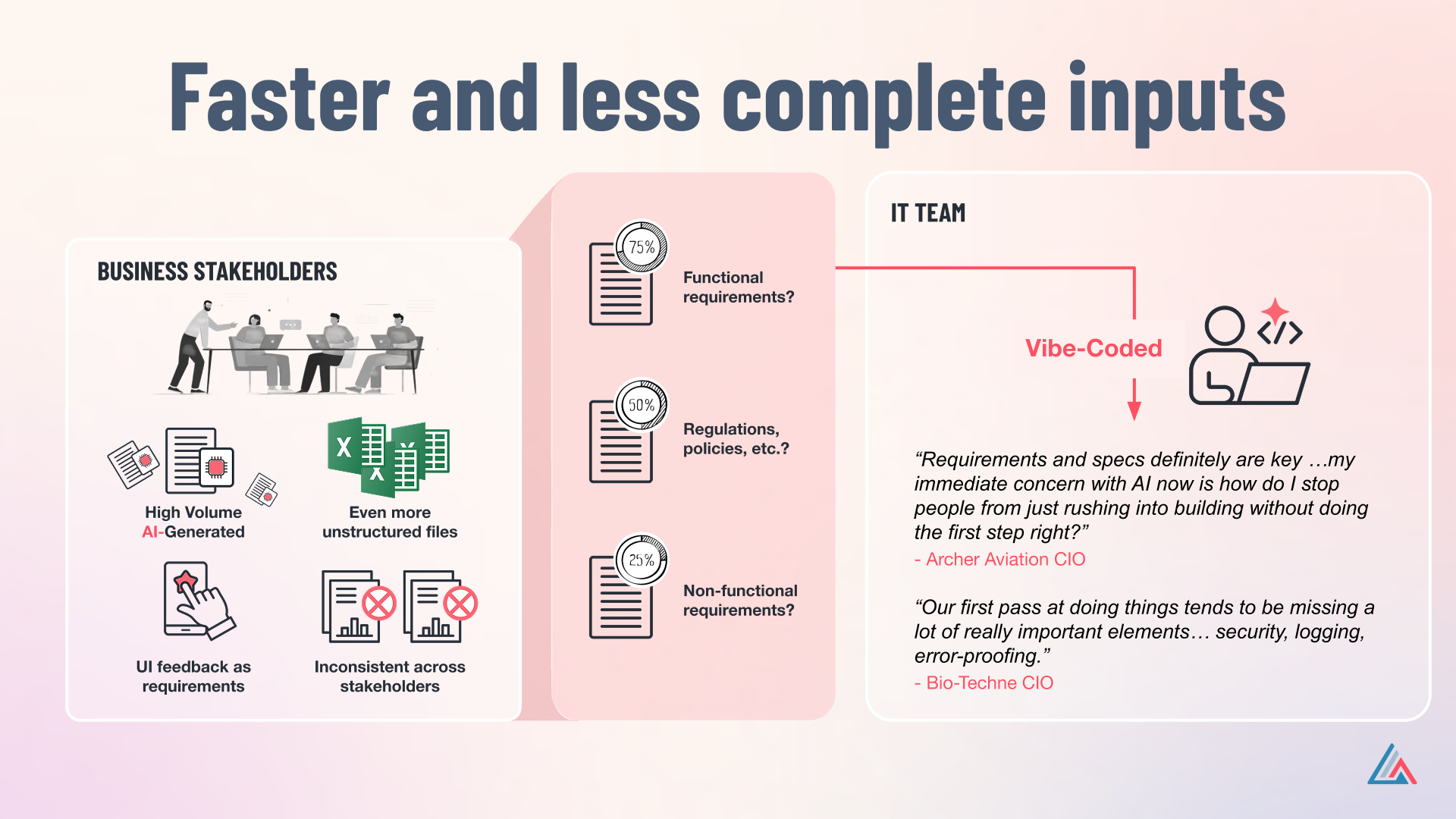
Volume goes up. More stakeholders generate "requirements" in parallel — finance, security, the business owner, compliance — each producing their own version. Reverse-engineered legacy systems produce hundreds of pages of regenerated specs no human can absorb end-to-end. A CIO at an aviation manufacturer asked me, half-joking: "Has anybody actually read the AI-generated documents?"
Completeness goes down. Non-functional requirements — security, logging, performance, governance, regulatory — get progressively skipped. The LLM wasn't prompted for them. The human didn't think to add them. A CIO at a biotech instrumentation company described it this way: "Our first pass at doing things tends to be missing a lot of really important elements — security, logging, error-proofing."
Drift compounds. Two stakeholders ask for the same thing in slightly different ways. Neither version gets reconciled. The build references whichever one happened to land on the developer's desk first.
And in the worst case, the requirements aren't requirements at all. People throw raw Excel files over the wall: "Just generate the app from this."
"How do I stop people from just rushing into building without doing the first step right?" — CIO, aviation manufacturer
Here's the part that explains the velocity gap.
Three specific things are missing from AI-generated requirements at enterprise scale: regulations and policies, enterprise governance constraints, and conformance to reference architecture. None of these are nice-to-haves. All of them have to exist before code can ship.
Security teams add gates because security policy wasn't captured upstream as a non-functional requirement. Governance frameworks thicken because compliance and regulatory constraints weren't encoded in the spec. Architecture review intensifies because AI-generated code drifts from enterprise reference architecture — a separate problem from missing NFRs, and one that compounds the load. Testing absorbs the volume: more PRs, bigger PRs, more code paths to validate, more environments to provision. Functional requirements exist, so test cases get written. There are just more of them, faster, against code that's been less carefully specified.
That's what the downstream stages are doing. Compensating. Every minute saved upstream creates additional work downstream, and the work compounds because each iteration of AI-driven code adds another version of the same gap.
That's why the math reads 21% developer productivity, while project velocity hasn't changed. The upstream gap and the downstream load aren't separate problems. They're the same problem, expressed at two ends of the lifecycle.
Spec-driven development is the direction — but the enterprise version is still open
The fix isn't more AI in code review. It isn't more AI in testing. Those tools have their own value, but they don't move the cycle. They optimize stages that aren't where the gap lives. The constraint is upstream.
The structural answer is a governed single source of truth: a specification that holds functional, non-functional, governance, and regulatory requirements together in one place. All stakeholders contribute to it. The build references it. Audit can point at it. It's the same artifact, all the way through the lifecycle.
The industry has a name for this direction. It's called spec-driven development, and it's no longer a fringe idea. Thoughtworks named it one of the most important practices to emerge in 2025. GitHub shipped Spec Kit, an open-source toolkit, in September 2025. AWS shipped Kiro, a spec-driven agentic IDE, in mid-2025. The category has a name and a growing toolchain.
Spec-driven development means treating the specification — not the code — as the system of record for what software is supposed to do, with functional, non-functional, governance, and regulatory requirements held together in one governed artifact. Code becomes the generated output. The spec is the truth.
That's the direction. What's still open is the enterprise version.
The enterprise version is different from the developer-toolkit version in ways that matter. It has to survive multi-stakeholder authorship — finance and security and the business owner and compliance all contributing to the same artifact without overwriting each other. Non-functional and regulatory requirements have to be first-class, not afterthoughts. Audit has to be able to trace any line of code back to the requirement that produced it, and back to the policy that justified the requirement. The spec itself has to be governed like the code it generates — versioned, reviewed, signed off, locked.
That governance also controls for prompt drift. When the spec is the system of record, every iteration — including AI-driven updates — works off the same artifact. The prompt becomes a transient instruction. The code stays anchored to intent. That's something prompt-only workflows can't deliver, and it's why a governed spec is more than an audit artifact. It's the only way to keep AI iteration consistent across versions of the same application.
That version, nobody has shipped yet.
The CIOs I spoke with reached for it independently, using different names. One of the insurers calls it autonomous SDLC. The other calls it AI DLC. A CIO at one of the banks calls it simply spec-driven development. The global investment services firm calls it end-to-end agentic personas. The regional bank describes a three-phase architecture. The naming hasn't settled — which is itself the signal. When several experienced enterprise CIOs in four weeks reach for the same end-state and can't agree on what to call it, the category is still being formed.
"This is all spec-driven development. Anybody who cracks this is going to win because nobody has cracked it yet." — CIO, global bank
The toolkit version of spec-driven development is being worked out in public — by GitHub, AWS, and others. The enterprise version — the one where the spec survives multi-stakeholder authorship, holds regulatory requirements first-class, anchors AI iteration against prompt drift, and gives audit a single artifact to point at — is the harder problem, and the more valuable one. That's what we've been building toward at Everest. The category itself is wide open, and the CIOs are already naming it.
If this topic interests you, I’d love to hear from you at sam.yen@everest-systems.com.